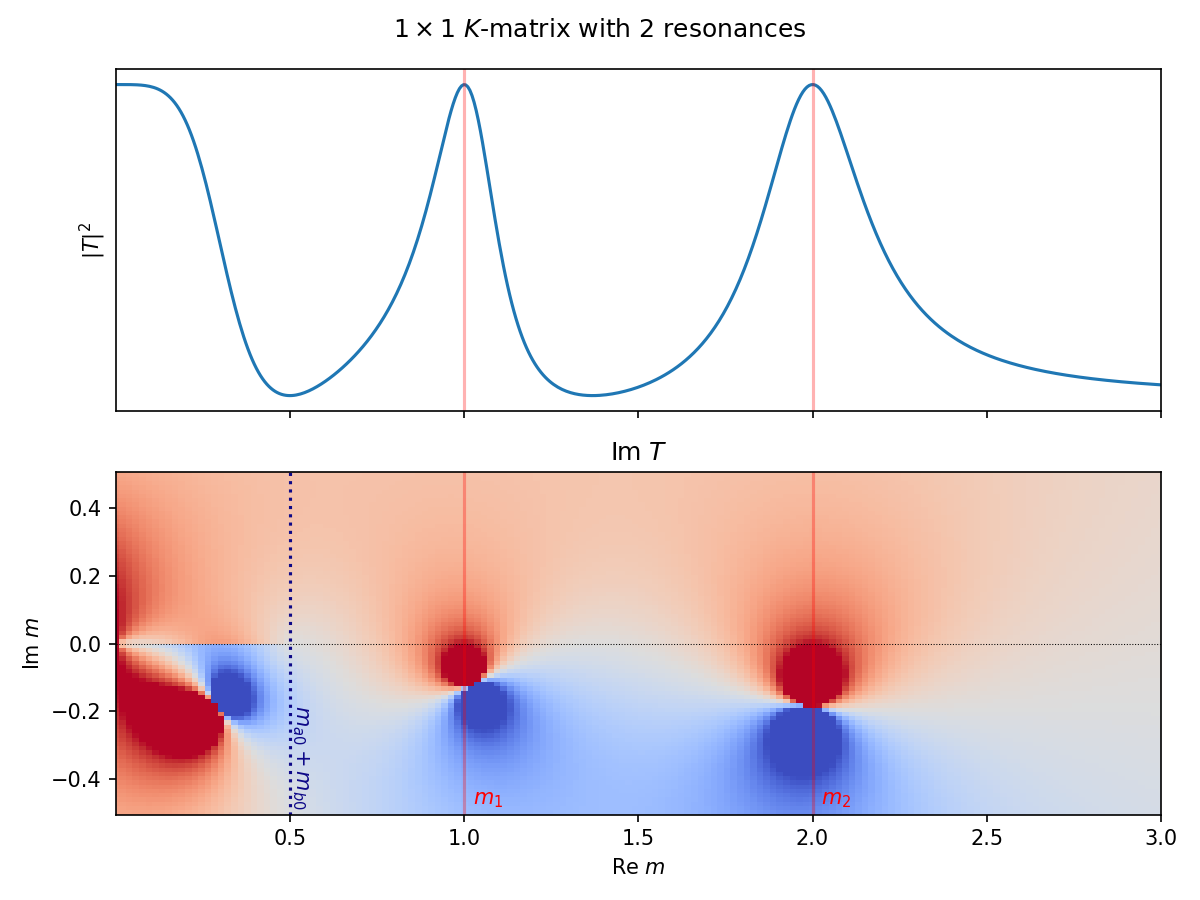
K-matrix#
While ampform does not yet provide a generic way to formulate an amplitude model with \(\boldsymbol{K}\)-matrix dynamics, the (experimental) kmatrix module makes it fairly simple to produce a symbolic expression for a parameterized \(\boldsymbol{K}\)-matrix with an arbitrary number of poles and channels and play around with it interactively. For more info on the \(\boldsymbol{K}\)-matrix, see the classic paper by Chung [Chung et al., 1995], PDG2021, §Resonances, or this instructive presentation [Meyer, 2008].
Section Physics summarizes [Chung et al., 1995], so that the kmatrix module can reference to the equations. It also points out some subtleties and deviations.
Note
The \(\boldsymbol{K}\)-matrix approach was originally worked worked out in K-matrix, Lorentz-invariant K-matrix, and P-vector. Those reports contained a few mistakes, which have been addressed here.
%matplotlib widget
Physics#
The \(\boldsymbol{K}\)-matrix formalism is used to describe coupled, two-body formation processes of the form \(c_j d_j \to R \to a_i b_i\), with \(i,j\) representing each separate channel and \(R\) an intermediate state by which these channels are coupled.

A small adaptation allows us to describe a coupled, two-body production process of the form \(R \to a_ib_i\) (see Production processes).
In the following, \(n\) denotes the number of channels and \(n_R\) the number of poles. In the kmatrix module, we use \(0 \leq i,j < n\) and \(1 \leq R \leq n_R\).
Partial wave expansion#
In amplitude analysis, the main aim is to express the differential cross section \(\frac{d\sigma}{d\Omega}\), that is, the intensity distribution in each spherical direction \(\Omega=(\phi,\theta)\) as we can observe in experiments. This differential cross section can be expressed in terms of the scattering amplitude \(A\):
We can now further express \(A\) in terms of partial wave amplitudes by expanding it in terms of its angular momentum components:[1]
with \(L\) the total angular momentum of the decay product pair, \(\lambda=\lambda_a-\lambda_b\) and \(\mu=\lambda_c-\lambda_d\) the helicity differences of the final and initial states, \(D\) a Wigner-\(D\) function, and \(T_J\) an operator representing the partial wave amplitude.
The above sketch is just with one channel in mind. The same holds true though for a number of channels \(n\), with the only difference being that the \(T\) operator becomes an \(n\times n\) \(\boldsymbol{T}\)-matrix.
Transition operator#
The important point is that we have now expressed \(A\) in terms of an angular part (depending on \(\Omega\)) and a dynamical part \(\boldsymbol{T}\) that depends on the Mandelstam variable \(s\).
The dynamical part \(\boldsymbol{T}\) is usually called the transition operator. It describes the interacting part of the more general scattering operator \(\boldsymbol{S}\), which describes the (complex) amplitude \(\langle f|\boldsymbol{S}|i\rangle\) of an initial state \(|i\rangle\) transitioning to a final state \(|f\rangle\). The scattering operator describes both the non-interacting amplitude and the transition amplitude, so it relates to the transition operator as:
with \(\boldsymbol{I}\) the identity operator. Just like in [Chung et al., 1995], we use a factor 2, while other authors choose \(\boldsymbol{S} = \boldsymbol{I} + i\boldsymbol{T}\). In that case, one would have to multiply Eq. (2) by a factor \(\frac{1}{2}\).
Ensuring unitarity#
Knowing the origin of the \(\boldsymbol{T}\)-matrix, there is an important restriction that we need to comply with when we further formulate a parametrization: unitarity. This means that \(\boldsymbol{S}\) should conserve probability, namely \(\boldsymbol{S}^\dagger\boldsymbol{S} = \boldsymbol{I}\). Luckily, there is a trick that makes this easier. If we express \(\boldsymbol{S}\) in terms of an operator \(\boldsymbol{K}\) by applying a Cayley transformation:
unitarity is conserved if \(\boldsymbol{K}\) is real. With some matrix jumbling, we can derive that the \(\boldsymbol{T}\)-matrix can be expressed in terms of \(\boldsymbol{K}\) as follows:
Lorentz-invariance#
The description so far did not take Lorentz-invariance into account. For this, we first need to define a two-body phase space matrix \(\boldsymbol{\rho}\):
with \(\rho_i\) given by (1) in PhaseSpaceFactor for the final state masses \(m_{a,i}, m_{b,i}\). The Lorentz-invariant amplitude \(\boldsymbol{\hat{T}}\) and corresponding Lorentz-invariant \(\boldsymbol{\hat{K}}\)-matrix can then be computed from \(\boldsymbol{T}\) and \(\boldsymbol{K}\) with:[2]
With these definitions, we can deduce that:
Production processes#
As noted in the intro, the \(\boldsymbol{K}\)-matrix describes scattering processes of type \(cd \to ab\). It can however be generalized to describe production processes of type \(R \to ab\). Here, the amplitude is described by a final state \(F\)-vector of size \(n\), so the question is how to express \(F\) in terms of transition matrix \(\boldsymbol{T}\).

One approach by [Aitchison, 1972] is to transform \(\boldsymbol{T}\) into \(F\) (and its relativistic form \(\hat{F}\)) through the production amplitude \(P\)-vector:
where we can compute \(\boldsymbol{\hat{K}}\) from (7):
Another approach by [Cahn and Landshoff, 1986] further approximates this by defining a \(Q\)-vector:
that is taken to be constant (just some ‘fitting’ parameters). The \(F\)-vector can then be expressed as:
Note that for all these vectors, we have:
Pole parametrization#
After all these matrix definitions, the final challenge is to choose a correct parametrization for the elements of \(\boldsymbol{K}\) and \(P\) that accurately describes the resonances we observe.[3] There are several choices, but a common one is the following summation over the poles \(R\):[4]
with \(c_{ij}, \hat{c}_{ij}\) some optional background characterization and \(g_{R,i}\) the residue functions. The residue functions are often further expressed as:
with \(\gamma_{R,i}\) some real constants and \(\Gamma^0_{R,i}\) the partial width of each pole. In the Lorentz-invariant form, the fixed width \(\Gamma^0\) is replaced by an “energy dependent” EnergyDependentWidth \(\Gamma(s)\).[5] The width for each pole can be computed as \(\Gamma^0_R = \sum_i\Gamma^0_{R,i}\).
The production vector \(P\) is commonly parameterized as:[6]
with \(B_{R,i}(q(s))\) the centrifugal damping factor (see FormFactor and BlattWeisskopfSquared) for channel \(i\) and \(\beta_R^0\) some (generally complex) constants that describe the production information of the decaying state \(R\). Usually, these constants are rescaled just like the residue functions in (15):
Implementation#
Non-relativistic K-matrix#
A non-relativistic \(\boldsymbol{K}\)-matrix for an arbitrary number of channels and an arbitrary number of poles can be formulated with the NonRelativisticKMatrix.formulate() method:
n_poles = sp.Symbol("n_R", integer=True, positive=True)
k_matrix_nr = kmatrix.NonRelativisticKMatrix.formulate(n_poles=n_poles, n_channels=1)
k_matrix_nr[0, 0]
Notice how the \(\boldsymbol{K}\)-matrix reduces to a relativistic_breit_wigner() in the case of one channel and one pole (but for a residue constant \(\gamma\)):
k_matrix_1r = kmatrix.NonRelativisticKMatrix.formulate(n_poles=1, n_channels=1)
k_matrix_1r[0, 0].doit().simplify()
Now let’s investigate the effect of using a \(\boldsymbol{K}\)-matrix to describe two poles in one channel and see how it compares with the sum of two Breit-Wigner functions (two ‘resonances’). Two Breit-Wigner ‘poles’ with the same parameters would look like this:
s, m1, m2, Gamma1, Gamma2 = sp.symbols("s m1 m2 Gamma1 Gamma2", nonnegative=True)
bw1 = relativistic_breit_wigner(s, m1, Gamma1)
bw2 = relativistic_breit_wigner(s, m2, Gamma2)
bw = bw1 + bw2
bw
while a \(\boldsymbol{K}\)-matrix parametrizes the two poles as:
k_matrix_2r = kmatrix.NonRelativisticKMatrix.formulate(n_poles=2, n_channels=1)
k_matrix = k_matrix_2r[0, 0].doit()
To simplify things, we can set the residue constants \(\gamma\) to one. Notice how the \(\boldsymbol{K}\)-matrix has introduced some coupling (‘interference’) between the two terms.
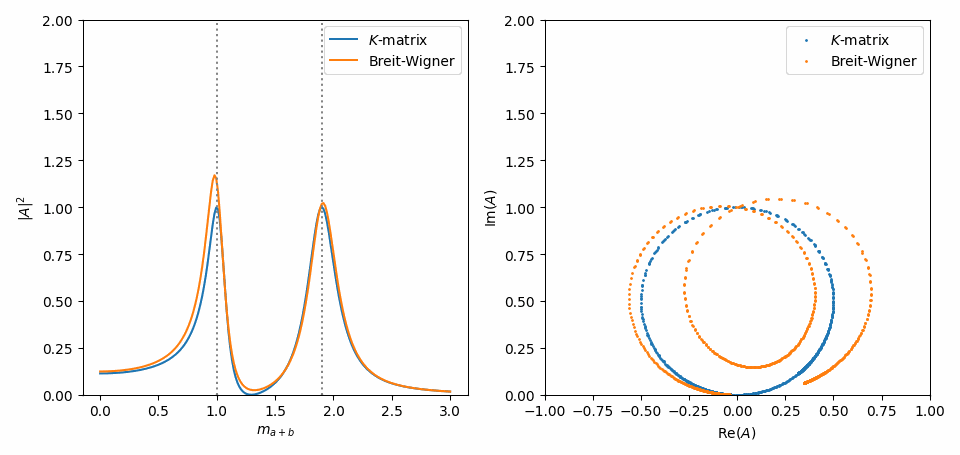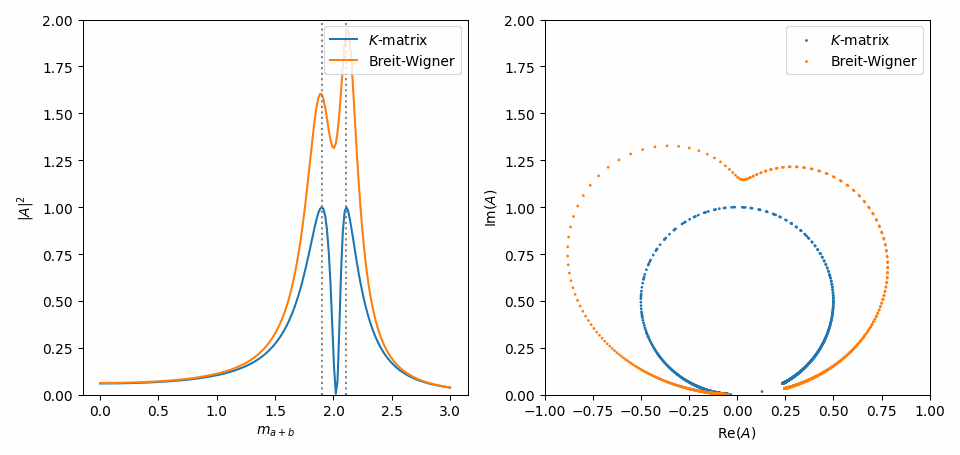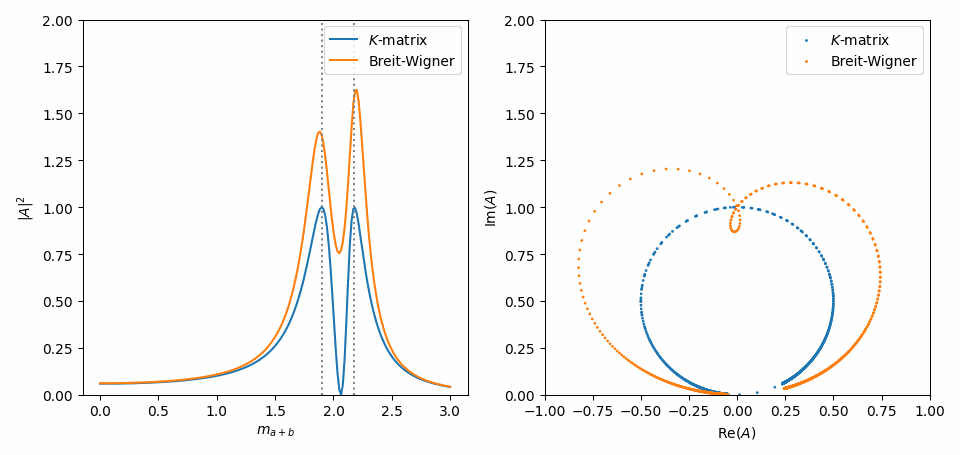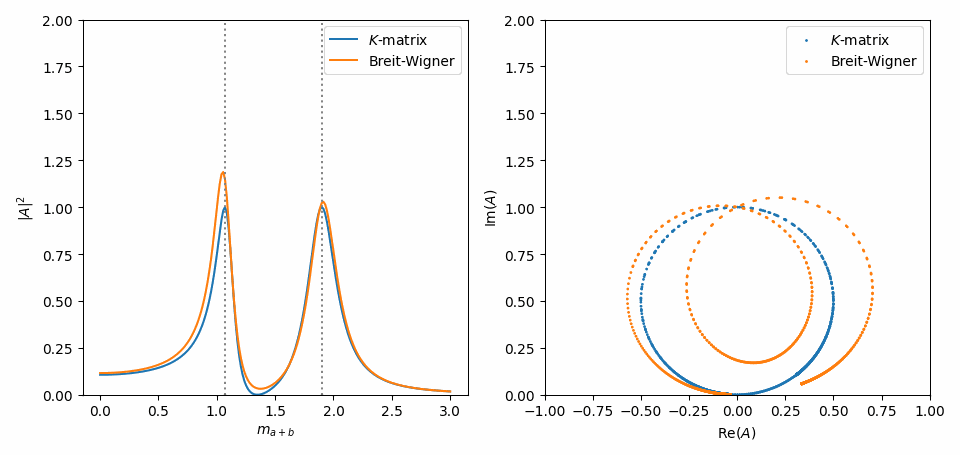
Now, just like in Inspect model interactively, we use symplot to visualize the difference between the two expressions. The important thing is that the Argand plot on the right shows that the \(\boldsymbol{K}\)-matrix conserves unitarity.
Note that we have to call symplot.substitute_indexed_symbols() to turn the Indexed instances in this Matrix expression into Symbols before calling this function. We also call symplot.rename_symbols() so that the residue \(\gamma\)’s get a name that does not have to be dummified by lambdify().
Relativistic K-matrix#
Relativistic \(\boldsymbol{K}\)-matrices for an arbitrary number of channels and an arbitrary number of poles can be formulated with the RelativisticKMatrix.formulate() method:
L = sp.Symbol("L", integer=True, negative=False)
n_poles = sp.Symbol("n_R", integer=True, positive=True)
rel_k_matrix_nr = kmatrix.RelativisticKMatrix.formulate(
n_poles=n_poles, n_channels=1, angular_momentum=L
)
rel_k_matrix_nr[0, 0]
Again, as in Non-relativistic K-matrix, the \(\boldsymbol{K}\)-matrix reduces to something of a relativistic_breit_wigner(). This time, the width has been replaced by a EnergyDependentWidth and some PhaseSpaceFactors have been inserted that take care of the decay into two decay products:
rel_k_matrix_1r = kmatrix.RelativisticKMatrix.formulate(
n_poles=1, n_channels=1, angular_momentum=L
)
symplot.partial_doit(rel_k_matrix_1r[0, 0], sp.Sum).simplify(doit=False)
Note that another difference with relativistic_breit_wigner_with_ff() is an additional phase space factor in the denominator. That one disappears in P-vector.
The \(\boldsymbol{K}\)-matrix with two poles becomes (neglecting the \(\sqrt{\rho_0(s)}\)):
rel_k_matrix_2r = kmatrix.RelativisticKMatrix.formulate(
n_poles=2, n_channels=1, angular_momentum=L
)
rel_k_matrix_2r = symplot.partial_doit(rel_k_matrix_2r[0, 0], sp.Sum)
This again shows the interference introduced by the \(\boldsymbol{K}\)-matrix, when compared with a sum of two Breit-Wigner functions.
P-vector#
For one channel and an arbitrary number of poles \(n_R\), the \(F\)-vector gets the following form:
n_poles = sp.Symbol("n_R", integer=True, positive=True)
kmatrix.NonRelativisticPVector.formulate(n_poles=n_poles, n_channels=1)[0]
The RelativisticPVector looks like:
kmatrix.RelativisticPVector.formulate(
n_poles=n_poles, n_channels=1, angular_momentum=L
)[0]
As in Non-relativistic K-matrix, if we take \(n_R=1\), the \(F\)-vector reduces to a Breit-Wigner function, but now with an additional factor \(\beta\).
f_vector_1r = kmatrix.NonRelativisticPVector.formulate(n_poles=1, n_channels=1)
symplot.partial_doit(f_vector_1r[0], sp.Sum)
And when we neglect the phase space factors \(\sqrt{\rho_0(s)}\), the RelativisticPVector reduces to a relativistic_breit_wigner_with_ff()!
rel_f_vector_1r = kmatrix.RelativisticPVector.formulate(
n_poles=1, n_channels=1, angular_momentum=L
)
rel_f_vector_1r = symplot.partial_doit(rel_f_vector_1r[0], sp.Sum)
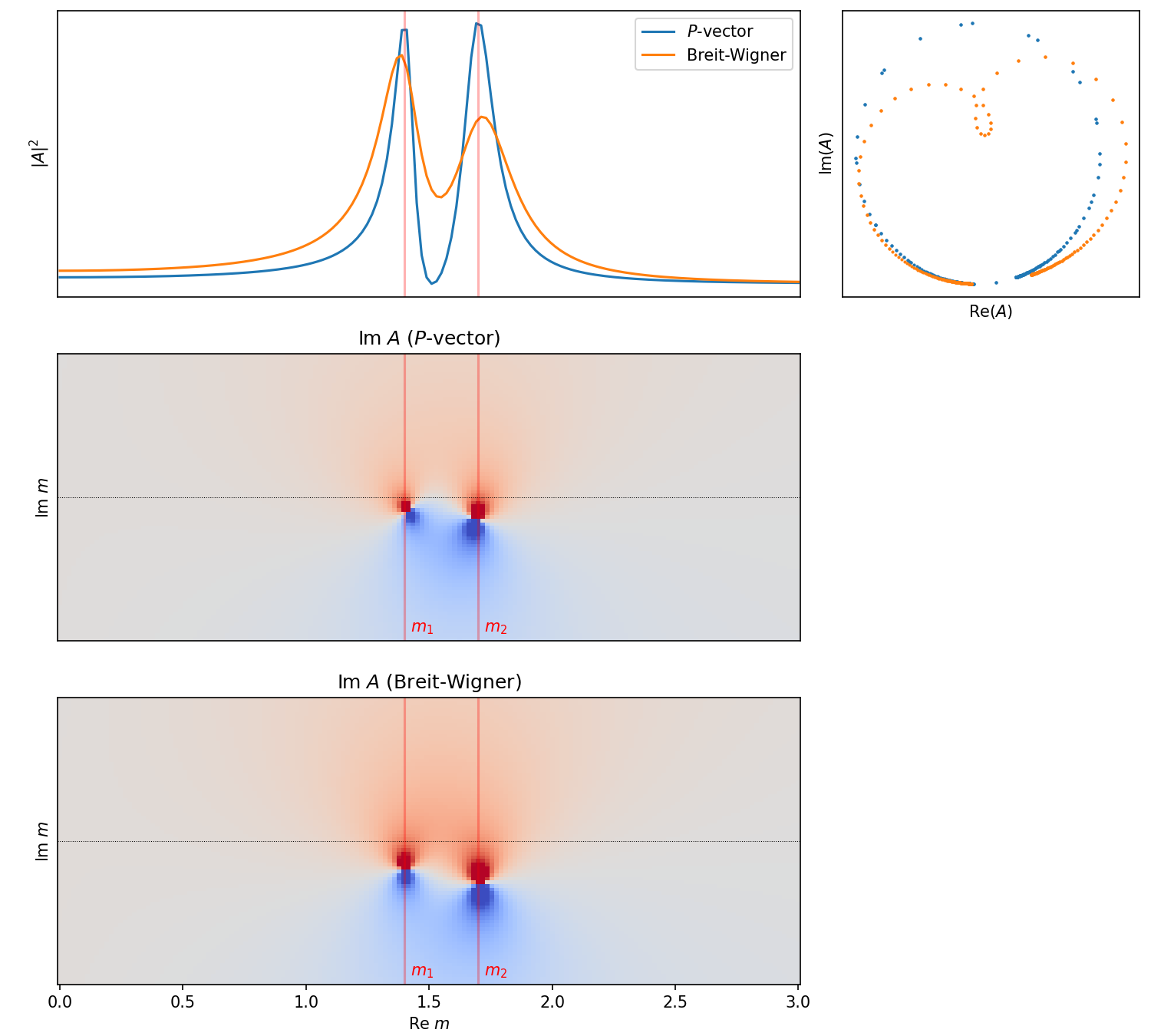
Note that the \(F\)-vector approach introduces additional \(\beta\)-coefficients. These can constants can be complex and can introduce phase differences form the production process.
f_vector_2r = kmatrix.NonRelativisticPVector.formulate(n_poles=2, n_channels=1)
f_vector = f_vector_2r[0].doit()
Now again let’s compare the compare this with a sum of two relativistic_breit_wigner()s, now with the two additional \(\beta\)-constants.
beta1, beta2 = sp.symbols("beta1 beta2", nonnegative=True)
bw_with_phases = beta1 * bw1 + beta2 * bw2
display(
bw_with_phases,
remove_residue_constants(f_vector),
)
Interactive visualization#
All \(\boldsymbol{K}\)-matrices can be inspected interactively for arbitrary poles and channels with the following applet:
plot(
kmatrix.RelativisticKMatrix,
n_poles=2,
n_channels=1,
angular_momentum=L,
phsp_factor=PhaseSpaceFactor,
substitute_sqrt_rho=False,
)